Scope: This part covers grapheme clusters — the final piece of correct Unicode text processing — backed by working implementations, benchmarks, and practical guidance on where to apply ICU.
TL;DR — Iterate grapheme clusters, not bytes or code points. If a human typed it, use ICU. The cost is 10×–16× on grapheme operations and grows with input size — apply it only where correctness requires it.
Grapheme clusters: what a "character" actually is#
A character in Unicode is not a byte, and not a code point. It is a grapheme cluster: the smallest unit that a human perceives as a single symbol.
The family emoji 👨👩👧👦 is one grapheme cluster made of seven code points and 25 UTF-8 bytes:
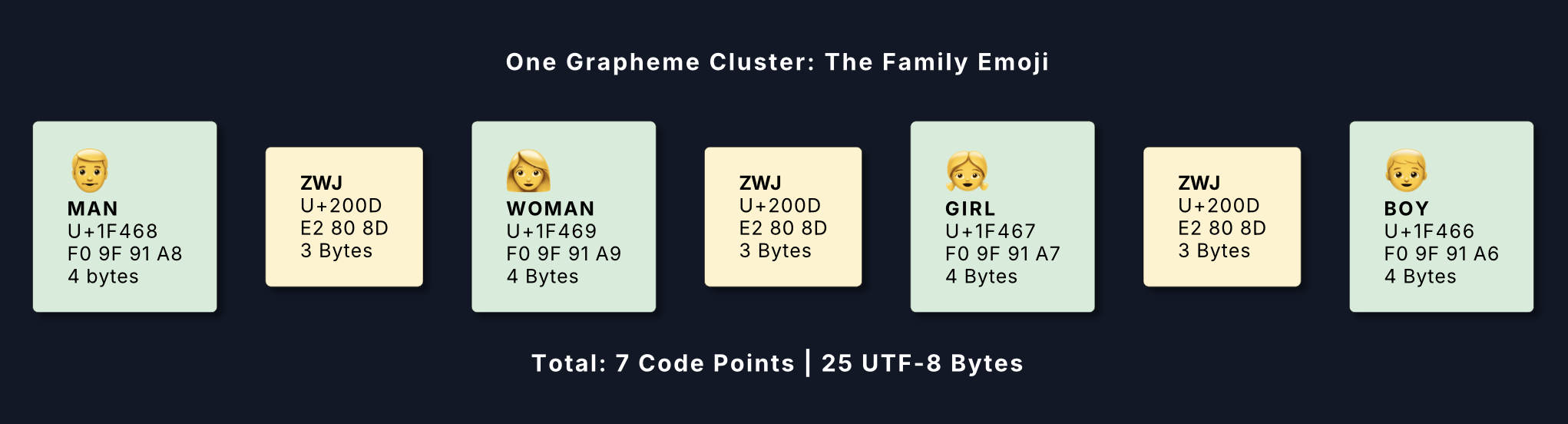
The ZWJ (Zero Width Joiner, U+200D) is an invisible character with no visual width that signals the renderer to join the adjacent emojis into one combined glyph. Without ZWJ the four emojis render separately; with it they combine. On renderers that don't support the sequence, ZWJ is safely ignored and the four individual emojis appear as fallback — that degradation is intentional. ZWJ occupies no pixels but does occupy bytes: each ZWJ character (U+200D) is 3 bytes in UTF-8.
The user sees one character. Any operation that splits at a byte or code-point boundary — substring, truncation, duplicate elimination — will produce incorrect results without grapheme awareness. Cutting between a ZWJ and the emoji that follows it leaves a dangling joiner that renders incorrectly.
The boundary rules that define what constitutes a grapheme cluster are in UAX #29 §3.1 — a set of rules (GB1–GB999) that specify exactly where cluster boundaries fall for every combination of code point properties.
ICU's BreakIterator walks grapheme cluster boundaries. Here is a deduplication function that removes duplicate grapheme clusters from a UTF-8 string in place:
void RemoveDupsUnicode(std::string &str)
{
if (str.empty()) return;
UErrorCode status = U_ZERO_ERROR;
icu::UnicodeString ustr = icu::UnicodeString::fromUTF8(str);
UBreakIterator *bi = ubrk_open(UBRK_CHARACTER, nullptr, nullptr, 0, &status);
if (U_FAILURE(status) || bi == nullptr) throw std::runtime_error("BreakIterator open failed");
// RAII guard: ensures ubrk_close runs on every exit path, including exceptions
std::unique_ptr<UBreakIterator, decltype(&ubrk_close)> bi_guard(bi, ubrk_close);
ubrk_setText(bi, reinterpret_cast<const UChar *>(ustr.getBuffer()), ustr.length(), &status);
if (U_FAILURE(status)) throw std::runtime_error("BreakIterator setText failed");
// Map UTF-16 code unit indices → UTF-8 byte offsets for in-place writes
std::vector<size_t> utf16ToUtf8;
utf16ToUtf8.reserve(ustr.length() + 1);
size_t byteOffset = 0;
for (int32_t i = 0; i < ustr.length(); ++i) {
utf16ToUtf8.push_back(byteOffset);
UChar32 cp = ustr.char32At(i);
if (cp <= 0x7F) byteOffset += 1;
else if (cp <= 0x7FF) byteOffset += 2;
else if (cp <= 0xFFFF) byteOffset += 3;
else byteOffset += 4;
if (U_IS_SUPPLEMENTARY(cp)) { ++i; utf16ToUtf8.push_back(byteOffset); }
}
utf16ToUtf8.push_back(byteOffset);
std::unordered_set<std::string> seen;
size_t write = 0;
int32_t start = ubrk_first(bi);
for (int32_t end = ubrk_next(bi); end != UBRK_DONE;
start = end, end = ubrk_next(bi))
{
size_t byteStart = utf16ToUtf8[static_cast<size_t>(start)];
size_t byteEnd = utf16ToUtf8[static_cast<size_t>(end)];
std::string key(str.data() + byteStart, byteEnd - byteStart);
if (seen.insert(key).second) {
if (write != byteStart)
std::memmove(&str[write], key.data(), key.size());
write += key.size();
}
}
str.resize(write);
}The complexity relative to the byte version illustrates why this matters architecturally. The byte version is a bitset and a single pass:
void RemoveDups(std::string &str)
{
std::bitset<256> seen;
size_t write = 0;
for (size_t read = 0; read < str.size(); ++read) {
unsigned char uc = static_cast<unsigned char>(str[read]);
if (!seen[uc]) {
str[write++] = str[read];
seen[uc] = true;
}
}
str.resize(write);
}ICU operates in UTF-16. The world speaks UTF-8. The translation layer between them is where the complexity lives. The manual utf16ToUtf8 index table in RemoveDupsUnicode exists because BreakIterator reports cluster boundaries as UTF-16 code unit offsets, but the original string is stored as UTF-8 bytes that need to be written in place. A simpler implementation could call icu::UnicodeString::toUTF8String() at the end to convert the result back — but that requires building a separate output string rather than operating in place, which adds an allocation and a copy. The index mapping trades memory for the ability to memmove directly within the original buffer.
The Unicode version must: convert to UTF-16, build that offset index, run the grapheme state machine, and track seen clusters as heap-allocated strings. There is no way to make this as cheap as the byte version — the operations are genuinely different.
Benchmark Results#
Benchmarks use Google Benchmark, which runs iterations until results stabilize and accounts for measurement overhead. Functions that mutate their input use PauseTiming() / ResumeTiming() to exclude the per-iteration copy from measurements. The benchmark code:
static void BM_RemoveDups_ASCII(benchmark::State &state)
{
const std::string src = "aabbccddeeffgghhiijjkkllmmnnooppqqrrssttuuvvwwxxyyzz";
for (auto _ : state) {
state.PauseTiming();
std::string s = src;
state.ResumeTiming();
ch01::RemoveDups(s);
benchmark::DoNotOptimize(s);
}
}
static void BM_RemoveDups_Unicode(benchmark::State &state)
{
// Each Greek letter appears twice — BreakIterator walks every grapheme cluster
const std::string src = "ααββγγδδεεζζηηθθιικκλλμμννξξοοππρρσσττυυφφχχψψωω";
for (auto _ : state) {
state.PauseTiming();
std::string s = src;
state.ResumeTiming();
ch01::RemoveDupsUnicode(s);
benchmark::DoNotOptimize(s);
}
}Results (Apple M2 Pro, arm64, Apple clang 17.0.0, C++26, ICU 78.2, -O3 -DNDEBUG):
| Benchmark | Time | Relative |
|---|---|---|
RemoveDups ASCII — bitset, in-place (52 bytes) |
617 ns | 1× |
RemoveDups Unicode — BreakIterator, grapheme clusters (96 bytes) |
6,522 ns | 10.5× |
RemoveDups ASCII — bitset, in-place (~1 KB) |
1,255 ns | 1× |
RemoveDups Unicode — BreakIterator, grapheme clusters (~1 KB) |
19,710 ns | 15.7× |
Note
The two inputs are not the same size (52 bytes ASCII vs 96 bytes Unicode for the small case; ~1 KB each for the large case). The ratio reflects both algorithmic overhead and the larger input; the analysis below accounts for both factors. Profile with your actual input sizes before drawing conclusions.The BreakIterator cost is structural and grows with input size. The 10.5× overhead on small strings becomes 15.7× at ~1 KB. This is expected: the ASCII bitset path reaches steady-state quickly (once all 26 letters are seen, remaining bytes are skipped with a single bitset check), while the Unicode path must convert every byte to UTF-16, build the full offset index, and look up every grapheme cluster in a heap-allocated hash set — all O(n) costs with no early-exit. The overhead is not from a poorly written loop; it is the irreducible cost of grapheme-aware processing.
Conversions accumulate. If the same string is processed repeatedly, convert once to icu::UnicodeString and keep it in that representation rather than converting on every operation.
Where this matters#
Display and truncation. Splitting a string at a byte or code-point offset can produce invalid UTF-8 or split a grapheme cluster in half. Text editors, terminal emulators, and any UI that truncates to a display width must use grapheme-aware boundaries. Cursor positioning and column width calculations break at cluster boundaries — a terminal that naively counts code points will misplace the cursor after a multi-codepoint emoji.
String length and width. The length of a string is not the width of its display. A string of 5 code points that are all fullwidth characters (CJK, fullwidth digits) displays as 10 columns — each takes 2. A string of 10 code points where 9 are combining marks stacked on a single base displays as 1 column. A string of 1 grapheme cluster might contain 25 bytes. Any code that assumes str.length() correlates with visual width is broken.
Substring and slicing. Cutting a string at an arbitrary position will corrupt it if that position falls within a multi-byte code point or within a grapheme cluster. Safe substring operations must be grapheme-aware.
When std::string is sufficient. Internal tokens, protocol keywords, configuration keys, and any string whose character set is controlled and ASCII-only do not need ICU. The overhead is real; apply it where the correctness gap is real too.
Summary#
- Grapheme clusters are the atomic unit of text, not bytes or code points;
BreakIteratorgives you what a user would call "one character." - ICU provides complete Unicode text processing: normalization, case-folding, and grapheme segmentation.
- Performance cost: 3×–4× for normalization and case-folding; 10×–16× for grapheme iteration depending on input size. The ratio worsens with longer strings — cache the
icu::UnicodeStringif processing the same string repeatedly. - The decision point: If a human typed it, it needs Unicode handling. For internal tokens and ASCII-only data,
std::stringis fine.
Final Summary#
Unicode text processing in C++ requires three pieces:
-
Normalization — Normalize to NFC before comparison or hashing. Cost: 3×–4× for small strings, up to 13× for longer ones. Essential for search and deduplication.
-
Case-folding — Use
foldCase()instead oftolower. Cost: well below normalization (no isolated benchmark; Part 1 measures them combined). Essential for any international text comparison. -
Grapheme segmentation — Iterate clusters, not code points or bytes. Cost: 10×–16× and grows with input size. Essential for correct display, truncation, and user-facing operations.
ICU provides all three. The cost is real but localized — apply it where the correctness gap exists. For anything else, std::string is fine.